每一次对话,都是重新开始
当我们与 ChatGPT、文心一言等大语言模型进行流畅的多轮对话时,很容易产生一种错觉:这个 AI 似乎记得我们之前说过的每一句话,它有着与人类似的记忆能力。
但真相可能让你惊讶:大模型本身完全没有记忆能力,每一次回应都是它的“第一次思考”。
大模型的“瞬时失忆症”
想象一下,你有一位极其博学却患有严重失忆症的朋友。每当与你交谈时,他都能对答如流、见解深刻,但一转头他就完全忘记刚才的对话——这正是大语言模型的真实写照。
从技术角度来看,大模型的本质是一个根据当前输入预测下一个词概率的生成系统。它并没有内部记忆机制来保存先前的对话内容,每一次请求都是一次全新的计算与生成。它所做的就像一个函数一样,你给出一个输入,它就给你一个输出。
许多人可能会困惑:既然如此,为什么像 DeepSeek 或 GPT 这样的模型似乎“记得”我们之前说的话?其实,你与之交互的并非纯粹的模型本身,而是在模型外层封装了记忆机制的应用——这些机制可能通过缓存、上下文拼接或memory系统实现,从而营造出“模型有记忆”的错觉。
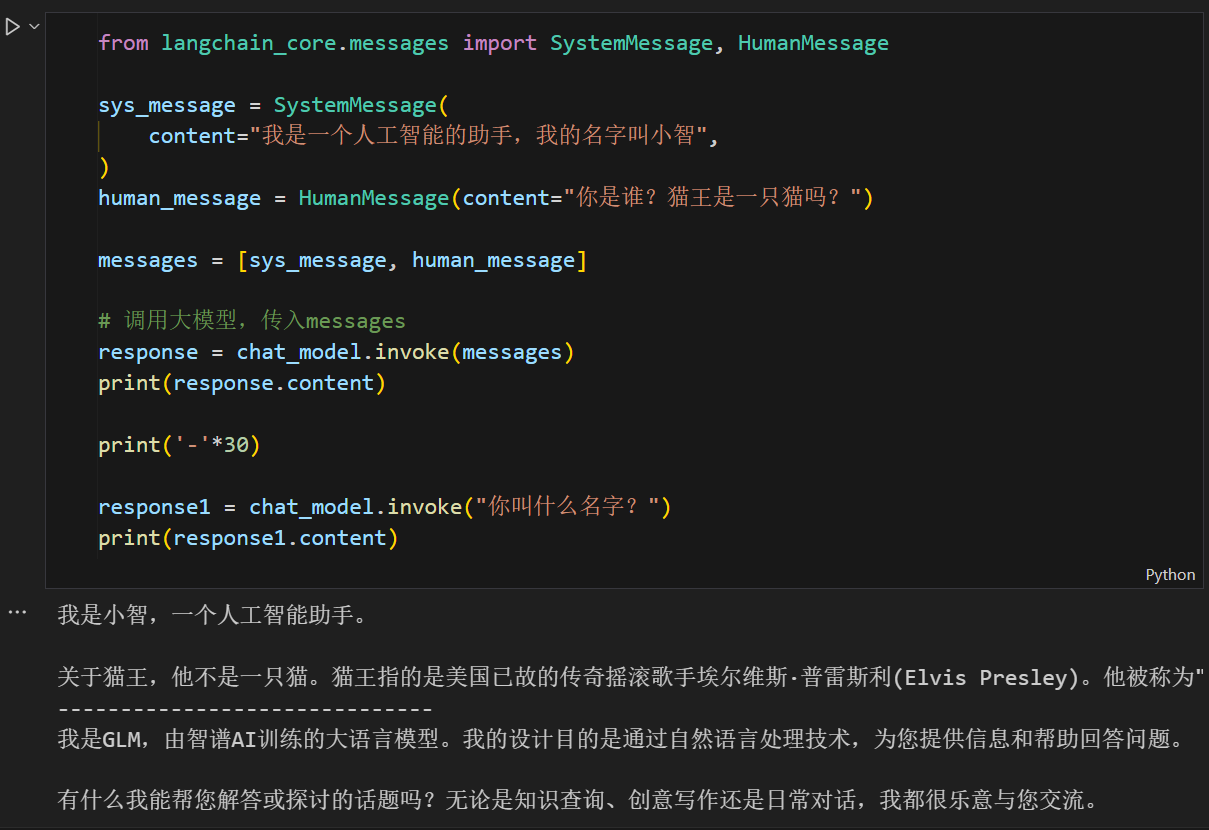
这两个调用是完全独立的。第二次 invoke() 没有携带之前的对话信息,因此模型无法记得“自己叫小智”。这说明模型本身没有记忆,每次调用都是全新的预测过程。
多轮对话的魔法:上下文窗口
既然模型本身没有记忆,那为什么我们可以进行连贯的多轮对话呢?
答案在于模型的上下文窗口(Context Window)机制。
上下文窗口指的是模型在一次推理中能“看到”的最大输入范围(以 token 为单位),模型通过分析这些文本内容来生成合理的回复。
实际上,每次请求时,应用端会把完整的对话历史重新打包为输入,一并传递给模型:
- 你的第一次提问: “推荐成都美食”
- 模型的第一次回答: “我推荐火锅、串串…”
- 你的第二次提问: “哪个最适合孩子?”
实际发送给模型的完整输入:
[
{"role": "system", "content": "我是一个人工智能助手,我的名字叫小智"},
{"role": "user", "content": "推荐一下成都的美食"},
{"role": "assistant", "content": "我推荐火锅、串串、烤肉,还有麻婆豆腐。"},
{"role": "user", "content": "哪个最适合带孩子吃?"}
]模型不是“记得”了之前的对话,而是“看到了”之前完整的对话记录。
这也解释了为什么当你开启新的聊天会话时,模型似乎“忘记”了之前的所有内容——因为应用层没有再传递之前的历史记录,模型实际上是在一个全新的上下文窗口中工作。
带来的限制
上下文窗口技术让连贯对话成为可能,但也带来了几个重要限制:
长度限制
每个模型都有最大的上下文长度,从早期的 4K token 发展到现在的 128K 甚至 200K token。这就像给模型一个固定大小的“工作记忆板”,超出范围就会被截断。成本问题
更长的上下文意味着更高的计算成本和 API 费用。每次传递整个历史,都需要为所有 token 付费。性能衰减
当上下文过长时,模型对较早信息的关注度会下降,可能出现中间塌陷现象——模型更关注开头和结尾的内容,模型对上下文中间部分的信息关注度降低,可能遗忘细节。
开发者视角
理解大模型无记忆这一特性,对开发者构建 AI 应用至关重要:
1. 主动维护对话历史
直接调用大模型 API 时,记忆责任完全在开发者肩上:
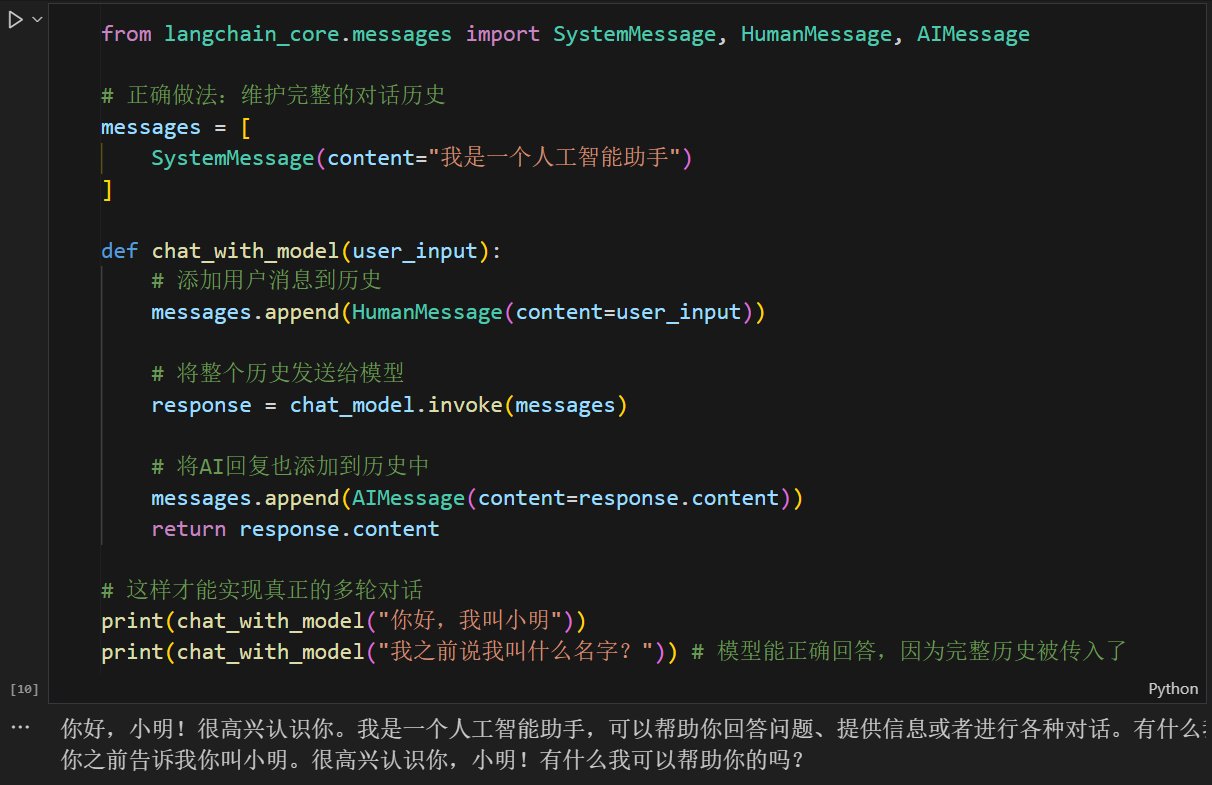
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
# 正确做法:维护完整的对话历史
messages = [
SystemMessage(content="我是一个人工智能助手")
]
def chat_with_model(user_input):
# 添加用户消息到历史
messages.append(HumanMessage(content=user_input))
# 将整个历史发送给模型
response = chat_model.invoke(messages)
# 将AI回复也添加到历史中
messages.append(AIMessage(content=response.content))
return response.content
# 这样才能实现真正的多轮对话
print(chat_with_model("你好,我叫小明"))
print(chat_with_model("我之前说我叫什么名字?"))模型能正确回答,因为完整历史被传入了。
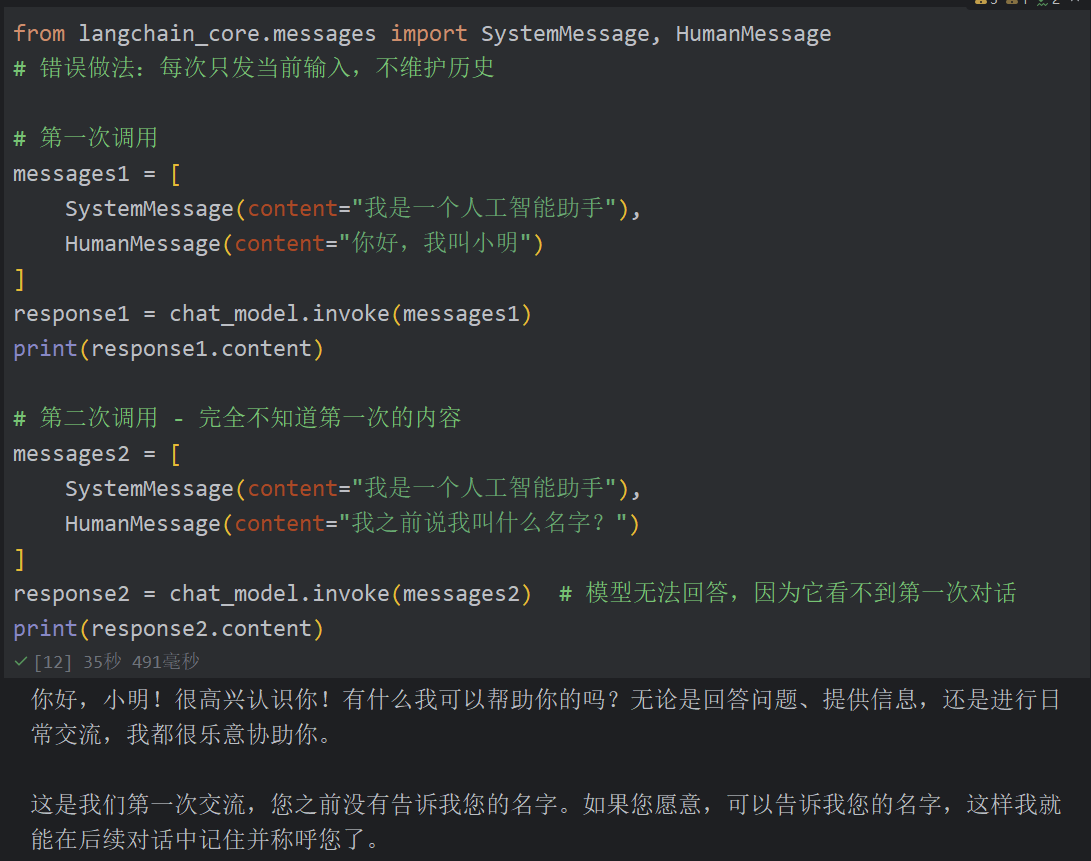
错误的API使用方式:如果每次只发送当前问题,不维护历史,模型就会”失忆”:
from langchain_core.messages import SystemMessage, HumanMessage
# 错误做法:每次只发当前输入,不维护历史
# 第一次调用
messages1 = [
SystemMessage(content="我是一个人工智能助手"),
HumanMessage(content="你好,我叫小明")
]
response1 = chat_model.invoke(messages1)
print(response1.content)
# 第二次调用 - 完全不知道第一次的内容
messages2 = [
SystemMessage(content="我是一个人工智能助手"),
HumanMessage(content="我之前说我叫什么名字?")
]
response2 = chat_model.invoke(messages2)
print(response2.content)模型无法回答,因为它看不到第一次对话。
2. 智能管理上下文
当对话超过模型上下文限制时,需要策略:
- 选择性保留重要信息
- 总结较早期的对话内容
- 按主题划分不同会话
3. 定义会话生命周期
在应用中需要明确定义:
- 何时开始新的会话(清空历史)
- 如何持久化存储重要信息
- 用户如何查询或重置对话历史
未来展望
当前的技术路线虽然有效,但仍有局限。业界正在探索更先进的记忆机制:
向量数据库 + 检索增强
将重要信息存入向量数据库,需要时智能检索相关片段,突破上下文长度限制(RAG 思路)。模型微调 + 持久化记忆
通过微调让模型掌握用户偏好,或开发专门的记忆存储模块。分层记忆架构
短期记忆(上下文窗口)+ 长期记忆(外部存储)+ 工作记忆(当前推理)的多层架构。
这些技术一旦成熟,未来的 AI 将可能真正实现“记忆”功能,而不仅仅是“阅读历史”。
大模型的“瞬时记忆”揭示了人工智能与人类智能的根本差异。我们觉得模型在“记忆”,实际上它只是在“阅读”我们提供的完整剧本。
理解这一点并不会削弱大模型的价值,反而能帮助我们更理性地设计和优化 AI 应用:
- 更精心地设计对话流程
- 更主动地管理对话状态
- 更宽容地对待模型的“遗忘”
下一次当你与 AI 助手畅聊时,不妨想想背后那个不断重新阅读整个对话历史的“失忆天才”。这份理解,或许能让你我成为更好的 AI 沟通者。



